When you capture new ideas, you want to share them with others. Back for the first time since the pandemic, Big Data LDN attracted more than 3000 vendors and experts for two days packed with data strategy, live speakers, and networking events. As I absorbed new ideas, I realised that a quick breakdown of the conference might provide you with new frameworks to more efficiently manage your data. In this blog, I’ll distill the opening keynote, outline OSO’s SpecMesh launch, and share tips to help you make the most of your next in-person conference.
Keynote: An introduction to Data Mesh
Opening Big Data LDN, Zhamak Dehghani took the stage to address a fundamental challenge that engineers and software architects face—siloed data. Zhamak is one of the leading voices in the data architecture field, and lately, she’s been focused on founding a new approach to data strategy, called DataMesh.
Zhamak made some good points. Although teams collect and act on customer data, they struggle to connect data from different sources and business functions. Then, when businesses silo data in separate departments and try to extract value from it, they run into friction and long lead times. Traditional data management, in which the Chief Data Officer or data team is the only one owning big data strategy, no longer works for the majority of digital businesses.
Data Mesh: A new approach to big data management
Right now, Zhamak’s DataMesh approach seems to be where the field is headed in the next three to five years. When OSO talks to our clients, we find that they want data and analytics that are streamlined, efficient, and available in real time. They want to adopt solutions that help them better share, access and manage their data. And if a new strategy emerges that helps them adopt these solutions, we’ll take it.
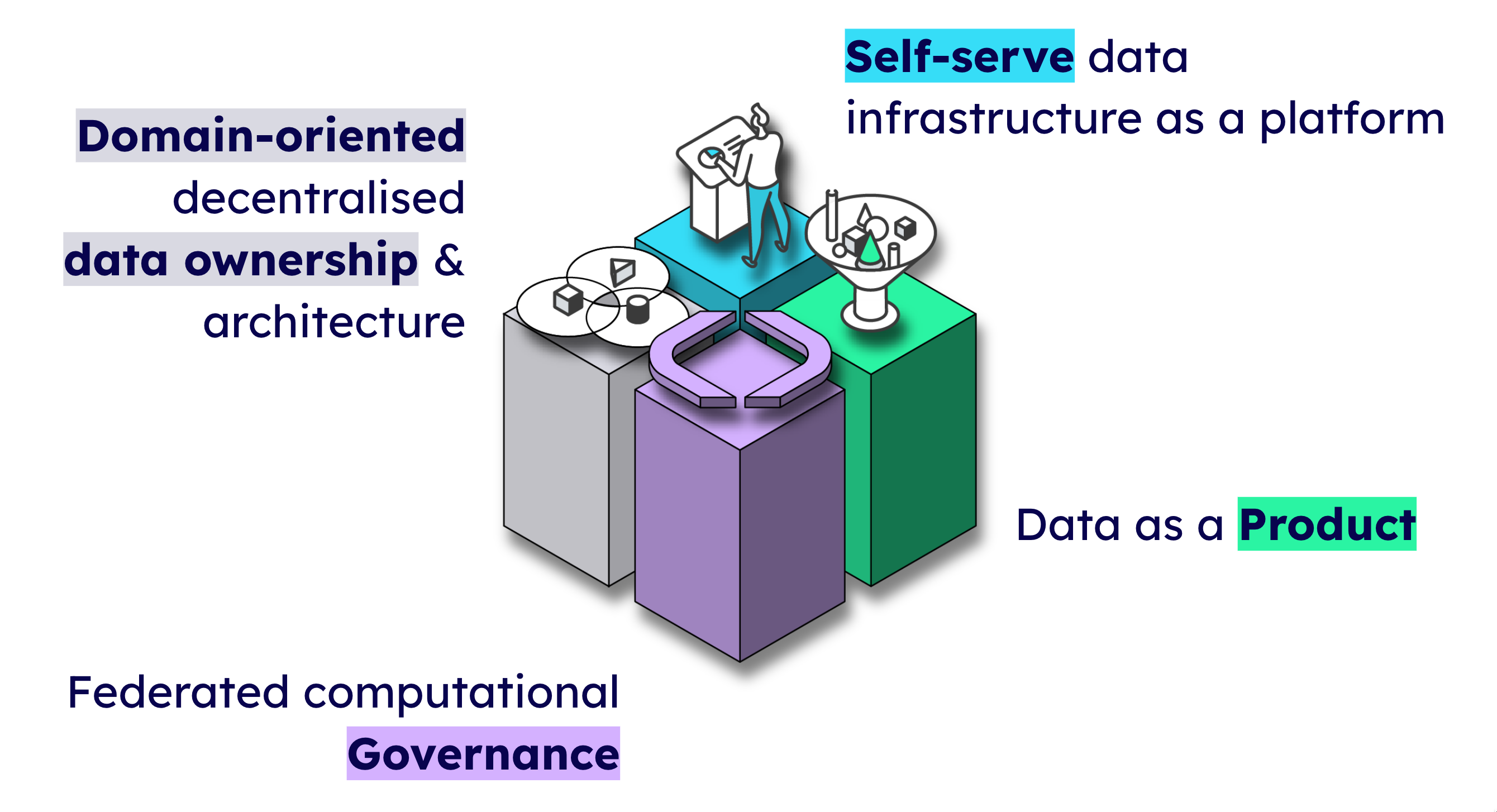
As opposed to traditional data architecture strategies, DataMesh operates with a more decentralised, multidimensional model. We’ll go into more detail on DataMesh and its principles in another post, but for the brief purpose of this blog, I’ll briefly share its four fundamental principles: data as a product, domain ownership, self-serve data infrastructure, and federated computational governance. These principles are meant to help data teams provide faster service, add more value for the end customer, and connect disparate sources of data across the business.
The four pillars of Data Mesh
Data as a product: Treat data like an asset, in which other teams and developers in the company are your customers. Make the data easy to access, trust, and query.
Domain ownership: Forget the large, centralised data team. Distribute data owners throughout different teams in the organisation. Domains handle data according to their needs and priorities.
Self-serve data infrastructure: Achieve a unified level of tooling throughout the business. Make this tooling easily accessible to employees with unequal levels of experience.
Federated computational governance: Create central governance policies but let individual domains handle the specifics.
The benefits of presenting SpecMesh at Big Data LDN
Later in the conference, I took the presentation stage alongside Neil Avery, CTO of Liquidlabs, to present an enterprise guide to building a data mesh. Data Mesh, in our heads, is a natural extension of the Central Nervous System model, in which the system runs via streams of events. But the current Data Mesh implementations are fragmented and extremely complicated to setup. As companies start to tout Data Mesh as the next big framework, they’ve started to confuse the space with a range of bespoke and commercial technology solutions.
The solution that OSO developed is an open-source, easy, readily-available set of standards for deploying Data Mesh in any size organisation. We’ll come out with an in-depth blog that explains the complete SpecMesh methodology, but here’s the core principles. With SpecMesh, data teams use specifications to drive how they provision resources, define the data product, and attribute domain ownership. Specifications clearly state which data resources to publish and subscribe, and the root.id attribute clarifies ownership.
The benefits of presenting SpecMesh at Big Data LDN
Presenting and launching SpecMesh at Big Data LDN was a standout experience. When people are curious and knowledgeable about the technology, the launch has a certain energy. Experts ask detailed questions. Business teams want to know how they might adopt a new deployment approach. Conference attendees start to discuss potential use cases and past projects. And after we wrapped our talk, Neil and I continued to answer questions about SpecMesh throughout the day.
Bonus: Watch our Big Data LDN conference footage
Tips for attending your next data conference
Leaving the conference, I couldn’t help reflecting back on Big Data LDN and other conferences post pandemic. For those of you now thinking about attending data and analytics conferences in 2023, I’d suggest a few next steps.
Plan your conference strategy. When the field is crowded, you need to cut through the noise. This year, I realised that the data industry truly has more solutions and marketing FUD than ever before. That means you need to go into conferences with a firm goal, state the problems you want to solve, and seek out developers and peers working on similar challenges.
Bring technical staff. As the data and analytics field matures, people attending these conferences now see past polished sales pitches. I’d bring people who can dig into the technical details and provide up-front value to conference attendees.
Attend after-hours events and meetups. Finally, as I was telling Rich and Ian, being back in conference meetings with actual people is a great experience. There’s something unique about meeting with like-minded people. You see their passion for data technologies in person, chat through new concepts and ideas over drinks, and, by the end, you’re surrounded by a group of buddies, feeling like kids batting around a new concept.
About OSO DevOps
We help teams to adopt emerging technologies and solutions to boost their competitiveness, operational excellence and introduce meaningful innovations that drive real business growth. Our developer-first culture, combined with our cross-industry experience and battle-tested delivery methods allow us to deliver the most impactful solutions for your business.
Looking for support applying emerging technologies in your business? We’d love to hear from you – get in touch.