How to Build a Real-Time Context Engine for AI Agents Using Event Driven Architectures
Sion Smith9 February 2026
8 mins read
A major enterprise technology provider recently acquired the leading commercial Kafka vendor for $11bn. That number alone should make every data engineer and the newly formed role of “AI Engineer” sit up. This was not a play for better plumbing. This was a bet that real-time data streaming is the foundational infrastructure layer for the next generation of AI agents.
As Hugo Lu noted in his analysis of the acquisition, IBM “figured out that all the hype around prompt engineering and RAG for AI agents was consolidating into ‘context engineering’, and that context engineering is at root a data problem.” The progression is clear: prompt engineering gave way to RAG, RAG is giving way to context engineering, and context engineering ultimately comes down to data variety, volume, and velocity.
Consider a practical scenario. A broadband company’s customer support agent needs to answer a query about a service outage. Engineers are posting updates to an internal chat every hour, support tickets are being raised across multiple channels, and the customer wants a real-time answer. Running last night’s batch job is useless. As Hugo put it, “the agent needs an up-to-the-second summary of what is going on in the world.”
The real-time context engine — a combination of historical and live operational data, served with governance and low latency — is the missing architectural layer that makes enterprise AI agents genuinely useful. This article breaks down what a real-time context engine actually is, why it matters, and how the OSO engineers are building one using Apache Kafka.
What Is a Real-Time Context Engine and Why Does RAG Not Solve This Problem?
The streaming industry had been dismissed for years as “Big Pipes” — unsexy, data plumbing work. Hugo described it as being “friendzoned” by the average tech pundit. That perception shifted overnight when IBM stumped up $11bn for it, recognising that those pipes are exactly what AI agents need to function.
In practical terms, a real-time context engine is a governed, low-latency serving layer that combines historical data with live operational state derived from business events happening right now. The broadband support agent needs to aggregate events from telephony systems, web chat transcripts, internal engineering communications, and ticket management platforms into a single coherent picture. Not yesterday’s picture. The picture from thirty seconds ago.
RAG — retrieval augmented generation — is the approach most teams reach for first. However, for real-time operational use cases, RAG assumes you have vectorised all your real-time information into a vector database before the agent can query it. For operational state that changes minute-by-minute — support ticket updates, engineer progress notes, order fulfilment statuses — the overhead of continuous vectorisation is architecturally wrong.
RAG is document retrieval. It pulls back previously stored knowledge from a vector database. That is brilliant for static knowledge bases, policy documents, and historical reference material. Context is different. Context is operational state — the current status of an order, a support ticket, a delivery — aggregated from live events as they happen. You would not vectorise every Teams message and every support ticket update just so an agent can access information that should be immediately available from the event stream itself.
Rather than enriching each Kafka event with an LLM call — stream-first thinking where you enrich every record with a slow, expensive, and unpredictable model — the real insight was to build rich, governed context and serve it to long-running agents on demand.
What Breaks First When AI Agents Do Not Have Real-Time Context?
The consequences of stale context are measurable, expensive, and in some cases dangerous.
Fraud detection is the canonical example. An AI agent tasked with fraud prevention that operates on stale data is worse than useless — it is actively harmful. There is absolutely no point in having an agent detecting fraud if it is working with information that is even minutes behind reality. The OSO engineers have seen this pattern repeatedly across enterprise engagements in financial services.
There is an emerging class of “ambient” or “always-on” agents that need continuous, up-to-the-second context to function. These are not agents that wait for a batch job or a human trigger to act. They are always on, continuously ingesting, reasoning, and reacting to data the moment it arrives.
Report generation is another area where stale context causes real damage. Agents generating reports with outdated data produce incorrect outputs that feed downstream processes, trigger automated workflows, and inform other agents making their own decisions. A compliance agent acting on a stale risk score, an inventory agent rebalancing stock based on yesterday’s demand signal, a pricing agent adjusting rates against outdated competitor data — each one compounds the original error. The damage cascades through every system and every agent that treats that output as a trusted input.
Then there is customer experience. When a customer queries an agent about an order and the agent cannot access the current state across finance, delivery, and logistics systems, the experience is poor. Data inconsistencies across siloed systems compound the problem — the agent might give a completely different answer depending on which system it manages to query first.
As Hugo noted, IBM was “sitting in sunless client canteens” on applied AI projects, seeing firsthand that the gap was not in model quality but in the freshness and structure of the data being fed to agents. The models were fine. The data was not.
Why Is Context Engineering, Not Prompt Engineering, the True Differentiator for AI Agents?
LLMs are rapidly commoditising prompt engineering. Models now analyse how people construct prompts and build those patterns into the next training cycle. This shift follows a three-stage progression:
The industry is moving through these stages fast. The models are getting so capable that the keywords you use in your prompt matter less and less. The OSO engineers have observed this directly: what used to require careful prompt construction now produces equivalent results with straightforward natural language.
The real differentiator is the data and context you provide. LLMs can generate an optimum prompt, but they cannot generate an optimum context. Context engineering is the discipline of designing a system that provides the right data, with the right business logic, with the right governance, to shape agent responses.
Think of it like a senior software engineer joining a new company. They know all the design patterns and understand the inefficiencies of using one language compared to another. However, if they do not know the coding standards, the API structures, the database schemas, or the technologies the company uses, they cannot deliver what is needed. The same is true for AI agents.
The data’s value is only realised when wrapped in business context. A list of conference attendees is pointless to a software company if it lacks the context of what industry those attendees operate in, what their purchasing patterns look like, and what stage of the sales funnel they represent. Business context is the secret sauce.
This creates a new requirement: context engineering evaluations. Same prompt, different context, iterated locally to understand which information produces the best agent responses. The OSO engineers identified this as a critical gap — and are currently iterating on patterns in Akka, Snowplow and Apache Kafka to validate context compositions.
What Does the Minimum Viable Architecture Look Like?
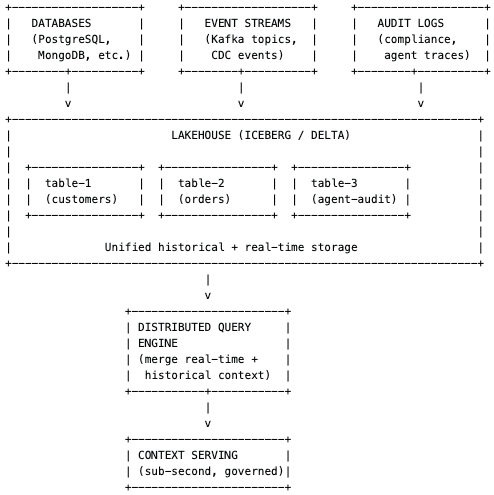
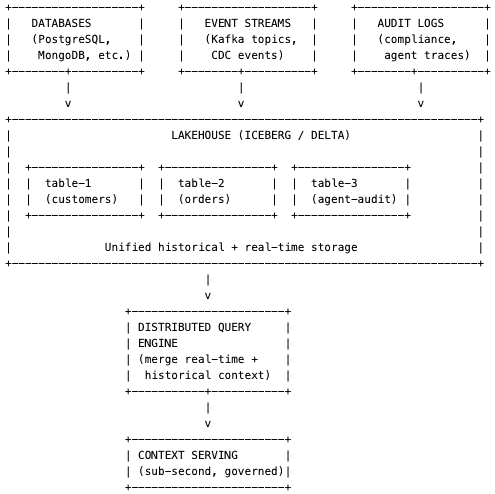
The agent needs a true representation of the whole state across the business. A minimum viable architecture needs three core components: historical data (past orders, customer profiles, transaction history), a materialised view of current operational state (the current status of an order moving through fulfilment), and low-latency serving so queries return in sub-second response times.
In simplest terms: take raw event feeds from Kafka, use stream processing to build fresh aggregates, store those aggregates in a low-latency serving layer, and expose them to agents via MCP.
Governance is non-negotiable. One customer’s data must never be exposed to another customer’s agent session — architecturally prevented, not just policy-controlled. For financial services, regulators need to audit a complete list of agent calls and responses with full traceability. If a human advisor needs to demonstrate why they made a particular recommendation, the agent must meet the same bar.
The event processing layer captures events in real time and orchestrates them into a materialised view combining historical and real-time data. Different event types require different capture mechanisms:
Apache Kafka remains the gravitational centre thanks to Kafka’s position as the default event backbone. Kafka Streams provides stateful aggregations through KTables — in-memory tables that maintain entity state as events flow through the system. For the OSO engineers, Kafka Streams is the path of least resistance for teams that already have Kafka deployed and want to build materialised context views without adding operational complexity.
Snowplow excels at capturing and structuring behavioural events — clickstreams, page views, and user interactions with rich, schema-validated context. Where Kafka captures the operational event stream (orders, transactions, system events), Snowplow captures the behavioural event stream (what the customer is browsing right now, how they navigate your site, what they searched for before contacting support). Snowplow has been building its own real-time context engine called Signals, aimed at developers building customer-facing agents. The OSO engineers see Snowplow aggregations as a natural complement to Kafka’s operational events, particularly for e-commerce and customer experience use cases.
Akka is the dark horse. Historically known as enterprise JVM messaging technology, Akka has been making a significant push into the agentic space. Its actor model provides a fundamentally different approach to stateful processing: rather than processing a continuous stream through a topology, you model each business entity as a lightweight, stateful actor. For context engines where the primary access pattern is “give me the current state of customer X across all interactions,” Akka’s entity-centric model can be more intuitive than stream-based aggregation. The OSO engineers have noted that Flink, while powerful, can be operationally too complex for the context engine pattern — Akka and Kafka Streams both offer simpler alternatives. See our Flink versus Akka post from October for more.
Enterprises are also seeing a massive transition into lakehouse architectures. Building a lakehouse using an open table format — Delta or Iceberg on top of object storage like S3 — allows you to consolidate data from databases, event streams, and audit logs into a single queryable layer. Building a view in the lakehouse that can be served in real time is a strong architectural choice for the context engine.
The OSO engineers expect the dominant pattern to be Kafka as the core event backbone with Snowplow providing structured behavioural context and either Kafka Streams or Akka handling the stateful aggregation layer, depending on the team’s existing technology stack and whether the access pattern is stream-oriented or entity-oriented.
Whatever real-time context engine architecture emerges must be open source and standards-based. Enterprises cannot trust a black box for this. They need to programmatically verify authentication, authorisation, and data source integration, and evaluate the outputs. Developers need to test locally, understand how context is composed, and assert against responses.
The debate around open-source sustainability in data — the well-worn pattern of free community adoption, VC fundraising, growing the community, then slowly gating features and raising prices — makes this even more pressing. All three of these technologies have open-source roots.
Conclusion
The shift from prompt engineering to context engineering represents a fundamental change in how enterprises build AI agent systems. The data — its freshness, governance, structure, and accessibility — is now the competitive differentiator, not the model or the prompt. Apache Kafka’s event-driven architecture provides the natural event backbone, Snowplow’s structured behavioural capture adds the customer context layer, and stateful processing through Kafka Streams or Akka provides the materialised views that agents need to act in real time.
The OSO engineers have seen across multiple enterprise engagements that the organisations making the most progress with agentic AI are those investing in their data infrastructure, not just their model selection. The real-time context engine is not a vendor product to be purchased. It is an architectural pattern to be built, tested, and iterated upon. 2026 will define what this architecture actually looks like. The question is not whether your agents will need real-time context. It is whether you will be ready to provide it.
Build your real-time context engine with confidence
Have a conversation with one of our Kafka engineers to discover how we can help you architect and implement a real-time context engine for your AI agents.