The OSO engineers have built kafka-backup as the open-source tool for this work, and the Enterprise MSK ZooKeeper-to-KRaft migration feature extends it with the cutover, validation, and evidence machinery that production migrations need. This article walks through the tool’s internal architecture — the design principles, the data flow through S3, the offset translation algorithm, the cutover protocol, and the cryptographic evidence bundle — so any platform team can understand exactly what the tool does and why before they run it against production.
Three Design Principles
Every architectural decision in the migration tool follows from three design principles:
1: No in-place migration. S3 is the replication channel between source and target. The source cluster is never modified — it remains a safe rollback target until the operator decides to decommission it. This is what makes the migration recoverable from anything short of cutover itself.
2: Deterministic state machine. Every phase transition is journaled. The migration can be resumed from any point, rolled back before cutover, or audited post-facto from the evidence bundle. There is no shell-script improvisation; the journal is the source of truth.
3: Offset continuity over offset identity. Target offsets will differ from source offsets — that is normal Kafka behaviour driven by compaction and replication timing. What matters is that consumers resume from the same message on the new cluster. The offset map is the artifact that translates between the two.
Those three principles are the difference between a Kafka data-copy tool and an MSK migration tool.
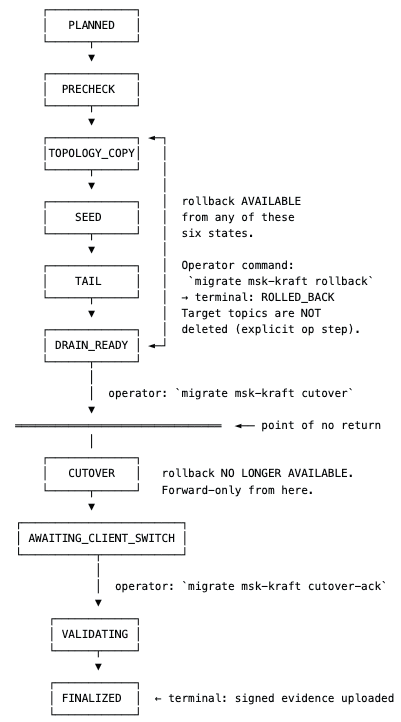
Each state corresponds to a phase with explicit pre- and post-conditions. Planned is a fresh migration with no mutations. Precheck runs read-only cluster analysis. TopologyCopy creates topics and ACLs on the target. Seed performs bulk data transfer through S3. Tail provides continuous replication from the seed boundary up to cutover. DrainReady indicates lag has converged and the tool is waiting for an operator. Cutover runs the freeze, sentinel publish, and offset translation. AwaitingClientSwitch is the tool waiting while the operator switches applications to the new bootstrap servers. Validating runs the five-check suite. Finalized is terminal — evidence signed and uploaded. RolledBack is the alternative terminal state, and Failed is reachable from any state and is resumable.
Every transition appends an entry to journal.jsonl, including the from-state, the to-state, the timestamp, and a reason string. On resume, the tool reads the journal, determines the tip state, and dispatches accordingly: planned-through-tail re-enters from the last non-failed state; DrainReady and AwaitingClientSwitch return exit code 10 to indicate “waiting for operator”; Failed walks backward through the journal up to four hops to find the last non-failed state and re-enters from there; terminal states are no-ops.
Embedded in the first journal entry is a resume fingerprint — a SHA256 hash of the source ARN, target ARN, and bucket names. On resume, the fingerprint is verified against the current configuration. This catches silent config changes between crash and resume — for example, somebody pointing the resume at a different target cluster by mistake. The migration refuses to continue against a configuration that does not match the one it started with.
Data Flow: The Seed Phase
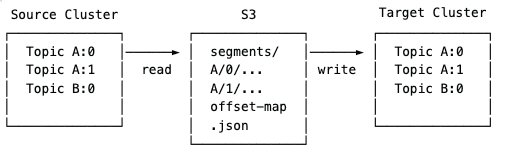
The seed phase performs a bulk copy of all source data through S3, decoupling source and target through durable intermediate storage.
Two engines do the work. BackupEngine reads from source partitions and writes S3 segments, each up to segment_max_bytes. RestoreEngine reads segments from S3 and produces them to target partitions. Between them, the offset map sidecar records, on a per-partition basis, the relationship between source offset ranges [src_first, src_last] and the corresponding target offset ranges [tgt_first, tgt_last]. The offset map lives at s3://<evidence_bucket>/<evidence_prefix>/<migration_id>/offset-map.json, durable from the moment seed begins.
The phase runs max_concurrent_partitions transfers in parallel — default is 4, configurable upward for clusters with high partition counts and ample bandwidth. Because S3 sits between source and target, neither cluster is exposed to the throughput characteristics of the other. The source can be drained at its own pace; the target can be filled at its own pace; failures on either side leave the durable S3 segments intact and recoverable.
Data Flow: The Tail Phase
After seed completes, tail phase bridges the gap between the seed snapshot and real-time:
Tail is a direct consumer-to-producer bridge. It consumes from the source starting at the seed end offsets, produces to the target, and updates the offset map continuously as new records flow. It tracks per-partition lag — calculated as source LEO − consumer position — and declares drain_ready when every partition has been within drain_max_partition_lag for the duration of drain_stable_window.
Tail progress checkpoints to S3. On resume, tail continues from the checkpoint — it does not re-stream from seed offsets — which keeps recovery cheap even for migrations that run long.
The Cutover Protocol
Cutover is the seven-step phase that locks in offset continuity. Each step is sequenced, and the sequence is enforced by the state machine.
Step 1 — Producer freeze
Producers on the source cluster are frozen, either via a webhook the tool calls into the operator’s application control plane, or via manual confirmation in an interactive terminal. The freeze creates a stable “end of source” boundary that everything downstream depends on.
Step 2 — Sentinel records
A sentinel record is published to every partition on the source:
The sentinel is the cryptographic equivalent of a high-water mark. It marks the exact boundary between “migrated data” and “nothing else after this point.”
Step 3 — Final drain
Tail keeps running until every sentinel has replicated from source to target. Once every sentinel has landed, the tool knows the target holds every record up to and including the migration boundary.
Step 4 — Consumer-group snapshot
All consumer-group committed offsets are fetched from the source cluster.
Step 5 — Offset translation
For each consumer group’s committed offset on each partition, the tool applies a single arithmetic translation:
source_first and target_first come straight from the offset map sidecar built during seed and tail. Three edge cases have explicit handling:
source_committed < source_first — the consumer was behind the earliest retained offset. The tool resets to start, translating to target_first.
source_committed > source_last — the consumer was ahead of the migration boundary. The tool clamps to target_last.
target_first missing — the partition has no data on target. The tool skips and logs a warning.
Each of these is a real production case. None of them is a guess.
Step 6 — Offset commit
Translated offsets are committed to the target cluster’s consumer-group coordinators via the Kafka OffsetCommit API. From the consumer’s perspective, when it reconnects to the target’s bootstrap servers, the group’s last-committed position is already where it should be. There is no auto.offset.reset decision to make.
Step 7 — Target offset-floor guard
Before the tool logs READY_FOR_CLIENT_SWITCH, it fetches target earliest and latest offsets for every migrated partition and verifies that the target log-start has not advanced past the first copied offset and that the target end offset is not behind the expected copied range. This catches retention or DeleteRecords truncation that a latest-offset-only drain check would miss — including the case where Kafka’s own retention policy silently truncates restored records because their preserved CreateTime timestamps put them outside the retention window.
Offset Continuity in Practice
The architectural payoff of the seven-step cutover is best shown directly. After cutover:
The consumer group’s committed offset points to the same message content on both clusters. When the consumer reconnects to the target, it reads msg-D next — exactly where it left off on the source. The offset numbers may differ (compaction, replication timing, the existence of the sentinel itself), but the offset map ensures the translation is correct. That is what offset continuity means in practice.
ACL Migration and IAM Mapping
The tool handles authorisation as a first-class concern, not as a manual post-step. ACL bindings are enumerated from the source via the DescribeAcls API and filtered to remove MSK internals — User:ANONYMOUS, bindings on __consumer_offsets and __transaction_state, and the kafka-cluster:ClusterAction cluster-level binding that MSK auto-manages.
Drift between source and target ACLs is handled by an explicit policy:
Policy
Source-only ACLs
Target-only ACLs
merge
Created on target
Left in place
replace
Created on target
Reported (not deleted)
refuse
Error — migration stops
Error — migration stops
refuse is the safe default for regulated environments where any unexpected ACL drift needs operator review before the migration proceeds. When the target uses IAM authentication, Kafka ACLs do not apply. The tool generates an access-map.json artifact mapping each source principal’s permissions to the equivalent IAM actions, which the operator then applies through their normal infrastructure-as-code pipeline. That boundary is deliberate — the migration tool tells the operator exactly what IAM access needs to exist; it does not make IAM changes inside the AWS account itself. For teams whose ZooKeeper-mode MSK cluster is also their last SCRAM cluster, this turns two migrations into one.
The Cryptographic Evidence Bundle
When validation passes, finalisation produces the artifact compliance teams care about: an Ed25519-signed JSON document uploaded to S3.
The bundle_json payload is comprehensive: migration ID, tool version, signed-at timestamp, configuration fingerprint, the complete state-transition journal, source and target cluster metadata snapshots, the full migration plan, the topology diff (topics created or updated and configurations applied), the ACL plan including which internals were filtered, seed statistics (records, bytes, partitions transferred), tail statistics (records replayed), per-partition drain state at finalize time, the cutover report (sentinel positions, freeze timing, all offset translations), and the validation report with per-partition detail for all five checks.
Evidence is uploaded to two S3 keys per migration. An attempt-scoped immutable key — <prefix>/<migration_id>/evidence-attempts/<timestamp>-<outcome>-<hash>.json — preserves every attempt, including failed ones, so the audit history is complete. A latest alias — <prefix>/<migration_id>/evidence.json — gives operators and auditors a stable pointer to the current authoritative result.
Each upload first attempts S3 PutObject with COMPLIANCE-mode Object Lock retention derived from the configured evidence.retention. If the bucket lacks Object Lock, the tool uploads without retention and logs a warning. For regulated workloads, Object Lock is the mechanism that makes the evidence tamper-proof for the configured retention period.
This is the artifact a homegrown migration cannot produce. A Slack thread, a few CloudWatch screenshots, and an operator’s memory of what happened are not evidence in any sense a compliance team or post-incident reviewer recognises. The signed bundle is.
Resume and Rollback
Two operational behaviours close the loop on the tool’s recoverability story.
Journal-based state recovery. The journal is loaded from S3 (or local directory), the tip state is determined, and execution re-enters from the appropriate phase. Failed states walk backward through the journal up to four hops — capped to prevent oscillation — to find the last non-failed state. The four-hop cap means the tool cannot get stuck retrying the same failed transition indefinitely; if recovery is not possible within four hops, the migration surfaces the failure to the operator rather than churning silently.
Rollback. Available from planned, precheck, topology_copy, seed, tail, and drain_ready — every state up to but not including cutover. Rollback verifies the resume fingerprint, performs a best-effort producer unfreeze if producers were frozen, uploads a rollback-report.json to the evidence bucket, appends the → rolled_back transition to the journal, and does not delete topics or data on the target. Cleanup of target topics is an explicit operator action, performed deliberately rather than as a side-effect of rollback. That is the conservative choice — the tool will not destroy anything the operator has not asked it to destroy.
The hard rule is that rollback is unavailable after cutover. Cutover is the irreversible moment in the migration, and the tool refuses to lie about that.
One Automated Tool to Fully Migrate MSK Zookeeper Clusters
A bespoke MSK ZooKeeper-to-KRaft migration project — provisioning the new cluster, configuring MirrorMaker, writing reconciliation scripts, building a runbook, holding a multi-team change window — typically runs to multiple weeks of effort and produces no machine-verifiable evidence. The OSO engineers’ kafka-backup tool replaces that with a single binary that owns the data flow, the state transitions, the offset map, the cutover sequence, the validation suite, and the signed evidence bundle.
The architecture of the tool is the migration. The state machine prevents improvisation. The offset map makes consumer continuity provable. The seven-step cutover bounds the irreversible window. The five-check validation refuses to sign off without proof. The cryptographic evidence bundle makes the result auditable for years afterwards.
The plan and precheck commands are free to run against production clusters today — no licence, no signup, no trial activation — and they generate the runbook, the IAM policy templates, and the cost estimate that any platform team needs to scope the migration before they commit to a window. For deeper architectural detail, the full architecture documentation covers every component referenced in this article.