Learn how Kafka support helped Drivvn migrate from batch to real time streaming data
Learn how Kafka support helped Drivvn migrate from batch to real time streaming data
Project Overview
- Drivvn’s lead platform engineers wanted to migrate from batch to real time streaming and processing to support asynchronous workflows, speed up processing times, and provide clients with enhanced analytics.
- After a series of technical workshops, Drivvn’s team decided to use Confluent’s managed solution for Kafka to cut down on overheads and costs of service.
- To quickly implement the solution, Drivvn partnered with our Confluent-certified developers to launch Kafka using the brand new Confluent Terraform Provider.
- OSO’s team created a functional production environment in six weeks, integrated Confluent Cloud with Drivvn’s legacy Azure infrastructure, and replaced Drivvn’s cron jobs with Apache Kafka’s ksqlDB solution.
Drivvn, the Digital Agency for Automotive Clients
Originally part of The Summit Group, Drivvn spun off as an independent agency on August 1st, 2020. Now, the agency has expanded to 35 UK-based engineers and staff, works with an international network of 100+ partners, and focuses exclusively on its area of expertise: automotive e-commerce.
Drivvn helps automotive original equipment manufacturers—from Jaguar to Citroën to Land Rover—drive online sales with a seamless online customer experience. These clients rely on Drivvn’s digital platform, which allows brands to customise their e-commerce sites, build omnichannel connections, and analyse customer clicks and behaviour.
Drivvn’s Digital Platform
Starting in 2019, Drivvn’s technical team rapidly built a platform to support the agency’s clients. Supporting more than 50 different site configurations and servicing 10 global clients, Drivvn’s platform provided a complete online store, offered back-office applications, and integrated with legacy manufacturing systems. (OEMs)
Scaling with the demand for EV vehicles, the original platform operated well. Drivvn’s ran its HTML applications on the web, pulled data from several API layers, ran the data through a Node proxy, and stored it in a combination of relational databases and an Elasticsearch-powered document store. In turn, Microsoft Azure fully managed both the databases and the Elasticsearch store—easing the load for Drivvn’s developers.
Challenge: Problems with Batch Data Processing
Rapid scaling came at the cost of technical debt, data flowed slowly—and at times, inconsistently—between applications. Clients couldn’t always see a single source of truth for the data, much less capture a full, 360-degree view of a customer’s experience. Drivvn also found it increasingly difficult to move data between applications, support asynchronous workflows, and provide clients with a seamless experience.
So Drivvn’s lead platform engineers decided to upgrade the platform and switch to Kafka’s stream processing technology. With event-driven, real-time data streaming, Drivvn would be able to build more features, increase value for its clients, and enhance its platform. Decoupling architectural component dependencies would also support streamlined development and remove the complexity in the batch jobs. So the team formed: Drivvn’s Lead Platform Engineer, Principal Engineer, Chief Product and Technology Office, and OSO’s Confluent-certified developers.
Decision-Making: Bringing OSO On Board to Adopt Apache Kafka
Drivvn’s technical team wanted to balance speed, cost, and expertise. If they tried to develop Kafka expertise in-house, the project would take significant time and might not work out. If they delayed the project, their platform’s technical debt would grow even further. Ultimately, Drivvn’s platform engineers decided to partner with OSO’s Confluent Kafka experts.
Since Drivvn’s technical team lacked experience with event-driven architectures, OSO launched the project with a multi-day technical discovery workshop. Over a series of sessions, our team identified Drivvn’s main challenges and established that Drivvn needed a solution that required minimal time to maintain and operate.
During the discovery workshops, we recommended that Drivvn use Confluent’s managed Kafka service, Confluent Cloud. Adopting Confluent Cloud, Drivvn would only pay for what they used: Confluent would handle the Kafka brokers, ZooKeepers, and disk space. In addition, Confluent’s fully-managed Apache Kafka service would allow Drivvn to more rapidly deliver product improvements—reducing the project’s length to six weeks.
Now, Drivvn and OSO just had to integrate Confluent Cloud with Drivvn’s Azure platform.
Roadmap: Integrating Confluent Cloud with Drivvn’s Platform
With a clear idea of what Drivvn wanted to accomplish, the OSO team set out three clear objectives for the stream processing project.
1. Establish a Local Development Environment
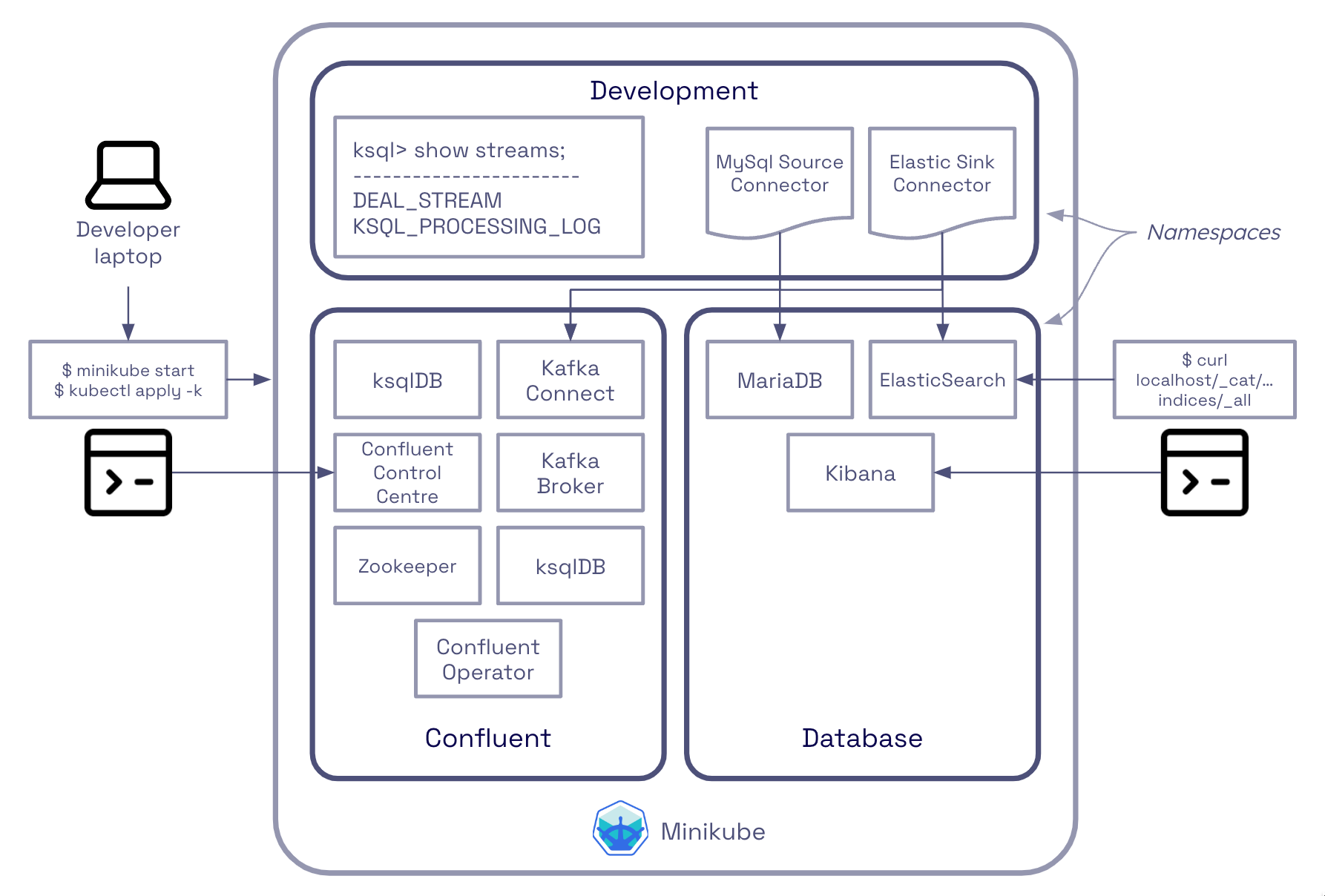
First, Drivvn’s team wanted to explore some of Kafka’s inner workings and experiment with event-driven solutions. Deploying onto Confluent Cloud’s managed Kafka service, developers often experience Kafka as a black box. To expose Drivvn’s team to Kafka, we therefore created a set of reusable Docker Compose files to support their engineers as they set up a local development environment to mimic a production environment.
To build the local environment, we created a BitBucket repository (cfk-local-setup) and deployed the following components.
- Configurations for a full-featured ‘Confluent for Kubernetes‘ cluster
- The process for building bespoke Confluent Connect images to allow for ElasticSearch/MariaDB Change Data Capture (CDC) integration
- A MariaDB database stub based on Drivvn schemas
- An ElasticSearch deployment for indexing
- Kafka Producer/Consumer GoLang examples
- Configurations for a full-featured ‘Confluent for Kubernetes‘ cluster
- The process for building bespoke Confluent Connect images to allow for ElasticSearch/MariaDB Change Data Capture (CDC) integration
- A MariaDB database stub based on Drivvn schemas
- An ElasticSearch deployment for indexing
- Kafka Producer/Consumer GoLang examples
2. Automate Environment and Deployment with Terraform
Next, we automated Drivvn’s Confluent Cloud infrastructure deployment using the brand new Confluent Terraform Provider. (To learn more, read our follow-up case study: Drivvn: Automating Kafka with Terraform-based GitOps.)
3. Replace Batch Process Cron Jobs
Finally, Drivvn wanted to leverage its new event-driven technology and in particular Kafka Connect framework and KsqlDB.
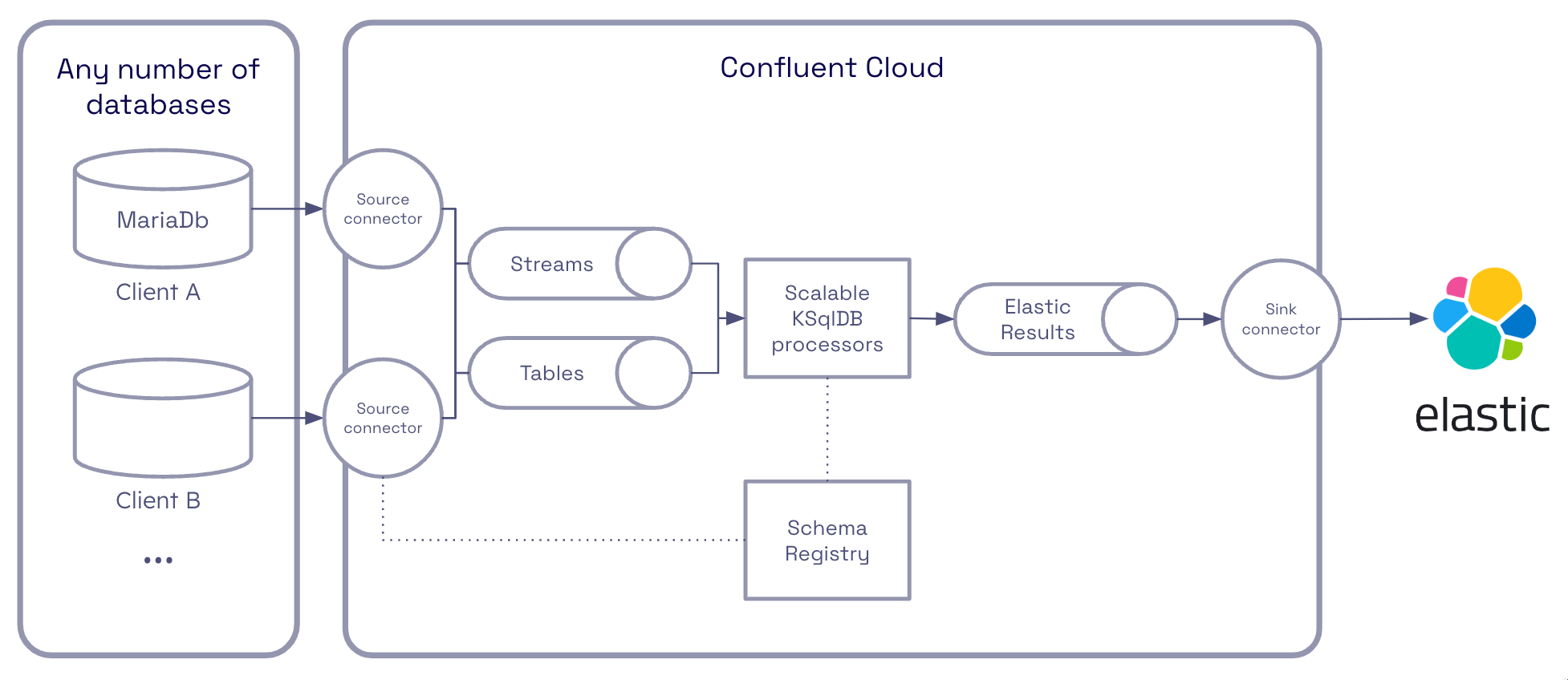
Originally, Drivvn’s technical team used cron jobs to push data from Drivvn’s databases to ElasticSearch. Since these cron jobs took place in scheduled intervals, their clients found it difficult to capture real-time customer data. If Drivvn switched to Kafka, it could migrate its batch processing to real-time streams, creating an interface for its automotive clients that displayed a real-time view of the customer experience.
For Drivvn to access real-time insights instead of waiting for cron jobs to compute complex OEM data, it needed to capture the present cron job logic which has grown over time. So as not to affect the existing platform, OSO deployed Kafka Connect and specifically the Debezium source connector for MySQL / MariaDB to capture and push all changes to the database into Kafka – known as CDC. Configuring the connector so that each table was mapped to an isolated topic, we could then leverage Confluent KsqlDB to quickly access and augment Drivvn’s data enabling processing data in motion rather than data in batches.
We also wanted Drivvn to be able to quickly enrich the data without reverting back to complex batching, using KsqlDB provided an interface that felt similar to Drivvn’s existing relational database. As a result, we could replace Drivvn’s cron jobs with Confluent Cloud’s KsqlDB solution, a solution built specifically for stream processing.
Problem-Solving: Left Joining in KsqlDB JSON Arrays
Using KsqlDB instead of native SQL to replace the cron jobs required us to adapt some of our tactics. Unlike SQL, Ksql completes full joins instead of left joins when the joining ID fields are null. Since we didn’t want to skip any records—which would happen with full joins—we needed to find a workaround. Here, we opted for staging tables, or flat tables that already had the joins made by SQL in the source database.
Once we addressed the left joining issue, we also had to sort a second challenge: data extraction. Since some parts of the data existed as JSON array objects inside a database column, working with JSON commands in Ksql turned out to be difficult. Although we considered writing a Kafka streams application for this we decided to incorporate a staging table for a second time, writing SQL to extract the data as coding and deploying another application would introduce more complexity – something we are trying to avoid.
In the end, we decided to simplify our solution. Instead of using staging tables, we streamed—from the source connector’s target topic—only the most essential data: Drivvn’s new and updated customer order information. We included the information’s primary key, date added, and date modified.
This strategy provided Drivvn with the data it needed, yet resolved our solution’s original roadblocks.
Interested in the technical code of how we did this? Check out our Github.
Result: Real Time Streaming Data
Drivvn’s technical team is now prepared to scale its real-time streaming analytics. In six weeks, we helped Drivvn’s platform engineers integrate their data sources hosted on Microsoft Azure with Confluent Cloud’s KsqlDB solution, establish a local development environment, and run a pilot that migrated batch data to real-time streaming.
Moving forward, Drivvn’s lead engineers intend to develop their own Kafka producers and consumers to write and read events to and from the Kafka cluster. These developments should not only help Drivvn’s technical team deliver a complete 360 view of their customers—they’ll pave the way for Drivvn to expand its expertise in Apache Kafka, experiment with new platform features, and enhance the customer journey for OEM brands around the globe.
Recap: OSO’s Contributions
- Provided expert advice on Confluent Cloud’s managed Kafka solution
- Led technical discovery workshops
- Outlined clear project objectives
- Deployed a fully-functional production environment
- Solved roadblocks through agile project management
- Ensured the security of Drivvn’s underlying operating systems
- Introduced real-time data streaming using KSQL